
Starting spring of 2023, I had the chance to join MIT D-Lab’s Biomass Fuel and Cookstoves group to research biochar production optimization using machine learning. It has been a great privilege working on this project with my PI, D-Lab Research Scientist Daniel Sweeney, and direct supervisor, Priyabrata Pradhan, a D-Lab postdoc and Fulbright Fellow. I’ve gained a tremendous amount of machine learning experience and have learned so much about the charcoal-making process. This summer, I had the chance to participate in the MIT Energy Initiative (MITEI) summer program and learned more about climate and energy accessibility, and the importance of work like ours in bridging the energy gap.
Seeking new insights on the relationship between feedstock and temperature for "green" charcoal production
Many people around the world still use charcoal because of its accessibility and its ability to enhance certain cuisines. However, charcoal is traditionally made with wood, and when many people depend on wood-based charcoal, it leads to issues like deforestation. The good news is that charcoal can be made from pretty much anything that has carbon in it. At D-Lab, we’re focusing on transforming biomass, or materials like agricultural waste, into green charcoal.
To make green charcoal from a non-traditional material like agricultural residues, we need to understand the relationships between the material and heating process and their effect on charcoal output. A lot of chemical reactions take place during the charcoal-making process, or pyrolysis, which are difficult to control. However, once we gain an understanding of pyrolysis, we can abstract our problem and more practically follow a general procedure in order to maximize charcoal output from a given material. (For example, We have X amount of hydrogen and carbon in our material, so we should use X temperature and heating rate.)
Since experimentation to figure out these patterns takes a long time, we instead used machine learning to analyze data from related, past experiments and doubly find those patterns for us.
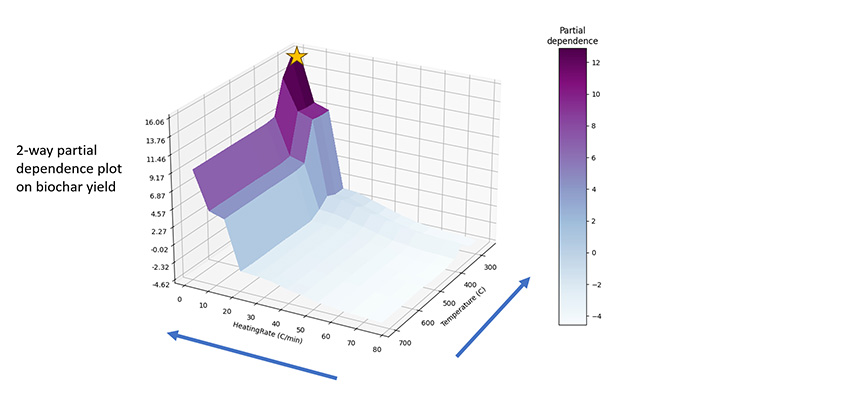
Lower temperature and heating rate led to higher biochar yield
My work began by using the machine learning model, Random Forest. I used 152 data points, collected from available research articles and spanning many different materials, from sludge to coconut shells. I then ran feature importance tests to understand what input data was most influential on the amount and quality of biochar produced. Here is a feature importance chart I generated for a Random Forest model trained on 80% of the collected data:
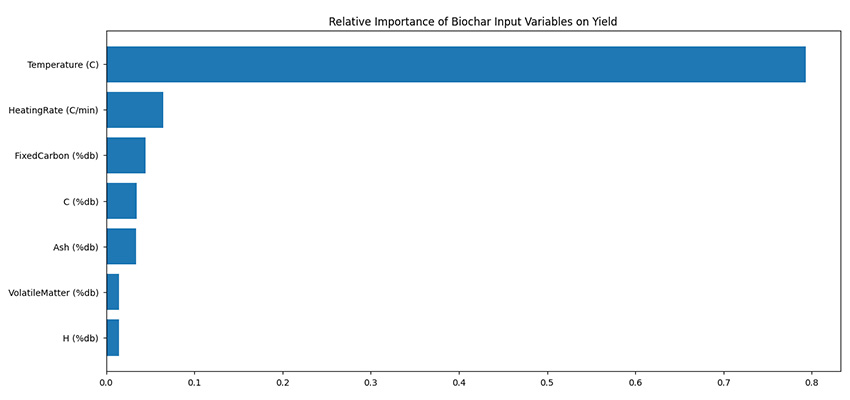
The feature importances on this chart are listed in descending order. Here, for biochar yield alone, the most influential process parameter, or feature, was temperature. In combination with other statistical tools, like Pearson Correlation Coefficient charts, we saw that higher temperatures often lead to lower biochar yield. Ultimately, we found that a combination of lower temperature and heating rate led to higher biochar yield.
Exploring alternate machine learning models
Over the summer, I continued analyzing the different factors of biochar production and explored different machine learning models with the hopes of finding one that could best predict biochar yield and quality from the same 152 data points. These other models were K Nearest Neighbors (KNN), Gradient Boosting, Lasso Regression, and Artificial Neural Networks (ANN-MLP).
And indeed, after learning about the different algorithms and implementing them, some of the models surpass Random Forest in terms of accuracy. One of them was Gradient Boosting, which works by penalizing errors as it “learns”. The other was ANN-MLP, a very sophisticated model that learns from its errors by sending information backwards in its decision-making and updating the weight, or importance, of a feature proportional to how much it’s responsible for error.
Interestingly, the best-performing model, Gradient Boosting, gave a slightly different feature importance chart than the one given by Random Forest:
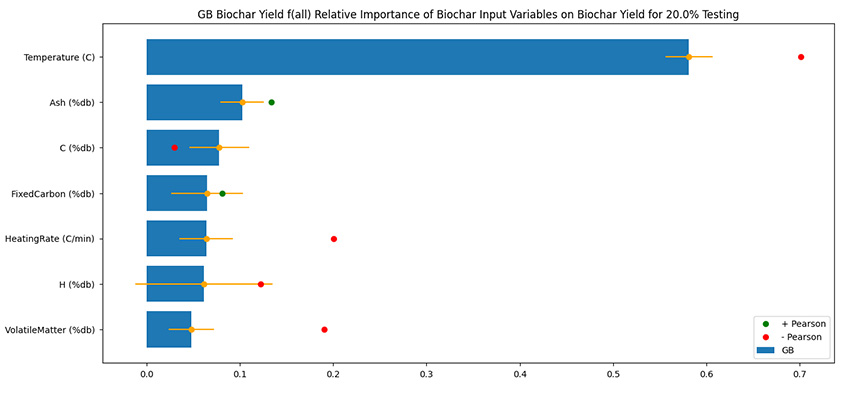
Ash comes out on top
Instead of “Heating Rate” being listed as the second most important feature, “Ash” was. This was a curious result! This leads me to my final remark, which is that more work and more representative data need to be collected before settling on the final result. We can also ask more questions, like which subsets of input data we can isolate to predict yield, or whether imputing missing variables affects model performance.
Information local biochar producers can use
Creating a quality model will help us determine a useful range to employ for certain features like temperature. This information will be useful for local biochar producers, including D-Lab partners around the world, and will aid in process improvement. This fall, I will help my supervisors produce a paper with our findings and explore some of these additional questions. This research will be shared with community partners associated with D-Lab, and I am very excited to see how this project will affect future biochar production processes so that more people can access clean-burning cooking fuels.
About the author: Johlesa Orm is a sophomore studying AI and Decision-Making at MIT. She enjoys taking part in projects that challenge her and allow her to contribute to improving communities and the environment.
More information
MIT D-Lab Biomass Fuels and Cookstoves research group
Contact
Dan Sweeney, MIT D-Lab Research Scientist, Biomass Fuels and Cookstoves lead